데이터 정의 및 EDA
[R/머신러닝/실습] 단순 선형회귀 분석
목표 제품적절성이 제품만족도에 미치는 영향 주제로 R을 이용한 단순 선형 회귀분석을 실시하고, 인공신경망을 이용한 선형 회귀분석을 python으로 실행하여 결과를 비교한다. 분석방법 SyncRNG패
robinlovesyeon.tistory.com
위 링크 참고
단순 선형회귀 분석
1) 데이터 호출
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from SyncRNG import SyncRNG
raw_data = pd.read_csv('E:/product.csv',encoding='cp949')
v=list(range(1,len(raw_data)+1))
s=SyncRNG(seed=42)
ord=s.shuffle(v)
idx=ord[:round(len(raw_data)*0.7)]
for i in range(0,len(idx)):
idx[i]=idx[i]-1
train=raw_data.loc[idx]
test=raw_data.drop(idx)
x_train = train.제품_적절성
y_train = train.제품_만족도
x_test = test.제품_적절성컬럼명에 한글이 있어서 encoding = 'cp949'옵션을 추가했다. 파이썬과 R에서 동일한 데이터로 홀드아웃 교차검정을 진행하기 위해 SyncRNG 패키지를 이용하여 데이터를 분할했다.
2) 모델 생성(인공신경망 경사하강법 적용)
class Neuron:
def __init__(self):
self.w = 1 # 가중치를 초기화합니다
self.b = 1 # 절편을 초기화합니다
def forpass(self, x):
y_hat = x * self.w + self.b # 직선 방정식을 계산합니다
return y_hat
def backprop(self, x, err):
w_grad = x * err # 가중치에 대한 그래디언트를 계산합니다
b_grad = 1 * err # 절편에 대한 그래디언트를 계산합니다
return w_grad, b_grad
def fit(self, x, y,lr, epochs=400):
for i in range(epochs): # 에포크만큼 반복합니다
for x_i, y_i in zip(x, y): # 모든 샘플에 대해 반복합니다
n=len(x)
y_hat = self.forpass(x_i) # 정방향 계산
err = -(2/n)*(y_i - y_hat) # 오차 계산
w_grad, b_grad = self.backprop(x_i, err) # 역방향 계산
self.w -= w_grad*lr # 가중치 업데이트
self.b -= b_grad*lr # 절편 업데이트
neuron = Neuron()
neuron.fit(x_train, y_train,0.1)
print(neuron.w)
print(neuron.b)뉴런 클래스를 생성한다. 클래스 내에 가중치(w), 절편(b)를 1로 초기화 하고 정방향, 역방향 계산하는 메서드와 모델링하는 메서드를 생성한다. 에포크수는 손실값이 수렴하기 시작할때의 값으로 설정해주었다.
실행결과 회귀식은 제품_만족도 = 0.7551 * 제품_적절성 + 0.71541 이다.
3) 예측 및 평가
predict=[]
predict = x_test * neuron.w + neuron.b
from sklearn.metrics import mean_squared_error, r2_score
mse=mean_squared_error(predict, y_test)
import math
math.sqrt(mse)
r2_score(y_test, predict)손실함수가 최소일때 W,b값으로 식을 새로 세워 test셋을 대입하여 예측값을 구한다. 예측값과 실제값의 차이를 제곱해서 평균(MSE)으로 회귀 모델을 평가한다. RMSE 값은 0.557795이 R2는 0.4969가 나왔다.
4) 시각화
plt.scatter(x_train, y_train, label='true')
plt.scatter(x_test, predict, label='pred')
pt1 = (1, 1 * neuron.w + neuron.b)
pt2 = (5, 5 * neuron.w + neuron.b)
plt.plot([pt1[0], pt2[0]], [pt1[1], pt2[1]],color='orange')
plt.legend()
plt.show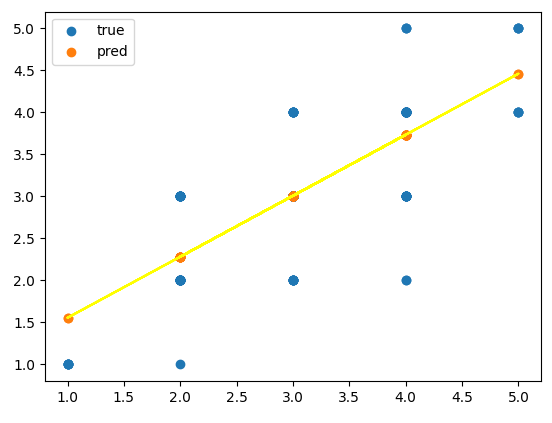
▲ 파란 점은 train셋을 표현한 것이고,
노란 선은 제품_만족도=0.7551*제품_적절성 + 0.71541을 설명하고 있다.
'python > 실습(project)' 카테고리의 다른 글
| [Python/딥러닝/실습] Keras를 이용한 다중 분류 분석(인공신경망) (0) | 2023.01.12 |
|---|---|
| [Python/딥러닝/실습] 로지스틱 회귀 분석 (0) | 2023.01.12 |
| [Python/실습] 의사결정나무를 이용한 BostonHousing 예측분석 (0) | 2023.01.03 |
| [Python/실습] 랜덤포레스트 모델을 이용한 위스콘신 유방암 데이터 분류분석 (0) | 2023.01.02 |
| [python/실습] xgboost를 이용한 위스콘신 유방암 데이터 분류분석 (0) | 2022.12.20 |

댓글