분석 목적
Zelensky 의 연설문에 기반한 빈도 분석에 따른 단어구름 생성을 기술한다. 그에 따라 현재 우크라이나가 러시아에 대해 취하는 태도를 살펴보고, 나아가 어떠한 부분에서 훌륭한 지도자로서의 연설문으로 평가받는지 분석해 보고자 한다.
데이터 정의
사용데이터: zelensky.txt
데이터 분석에 앞서 원본 텍스트 파일을 살펴보았다. 원본 파일은 우크라이나 원어 연설문을 영어로 번역한 후 다시 한국어로 번역한 버전이며, 일부 문단은 원어와 영어가 함께 기술되어 있다. 원문의 의미 훼손을 최소화하는 방향에 따라 아래와 같이 분석 데이터를 선별했다.
원본 출처 링크와 우크라이나어, 영어를 제외한 텍스트 전문
우크라이나어와 영어를 기반으로 한국어 번역을 수행한 텍스트이므로 제거하더라도 의미 분석에는 큰 영향이 없을 것으로 판단했다. 따라서 우크라이나어는 원본에서 제거했으며, ‘당신들’이나 ‘너희들’과 같이 불용어의 판단이 모호한 경우에 영어 번역본을 참고한다.
텍스트 전처리
1) library 호출 및 데이터 불러오기
library(KoNLP)
library(tm)
library(multilinguer)
library(wordcloud2)
library(stringr)
library(tidytext)
setwd('c:/Rwork')
raw_zel <- readLines("zelensky.txt", encoding = "UTF-8")
head(raw_zel)2) 1차 전처리 및 명사 추출
user_dic <- data.frame(term = c("우크라이나", "러시아"), tag = "ncn")
buildDictionary(ext_dic = "sejong", user_dic = user_dic)
raw_zel <- str_replace_all(raw_zel, "사람들", "사람")
raw_zel <- str_replace_all(raw_zel, "영웅들", "영웅")
raw_zel <- str_replace_all(raw_zel, "당신들이", "당신")
exNouns <- function(x){paste(extractNoun(as.character(x)),
collapse = " ")}
zel_nouns <- sapply(raw_zel, exNouns)
zel_nouns[1]‘우크라이나’와 ‘러시아’를 단어 사전에 추가하지 않고 단어 분석을 진행할 경우, 해당 단어 두 가지가 원문에서 5회 이상 등장함에도 불구하고 빈도수가 실제보다 적게 나온다. 따라서 우크라이나와 러시아를 단어 사전에 추가하는 과정을 거쳤다. 또한, ‘사람들’, ‘영웅들’과 같은 유의어의 경우에도 앞선 두 단어와 마찬가지로 실제보다 적은 빈도수가 도출되므로, ‘사람’, ‘영웅’과 같은 단어로 대체했다. 원문에서 “당신”은 바이든이나 유럽과 같은 청자를 직접 지시하고 있기에 빈도수를 높여주었다.
1차 전처리를 끝내고 extractNoun을 활용한 사용자 정의 함수를 통해 명사를 추출했다.
3) 말뭉치(corpus)생성 및 2차 전처리
zelcorpus <- Corpus(VectorSource(zel_nouns))
zelcorpus2 <- tm_map(zelcorpus, removePunctuation)
zelcorpus2 <- tm_map(zelcorpus, removeNumbers)
zelcorpus2 <- tm_map(zelcorpus, tolower)
myStopwords = c(stopwords('english'),
"때문", "이것", "그것", "들이", "해서",
"무엇", "저들", "이번", "우린", "우리")
zelcorpus2 <- tm_map(zelcorpus, removeWords, myStopwords)
inspect(zelcorpus2)
zelcorpus3 <- TermDocumentMatrix(zelcorpus2,
control = list(wordLengths = c(4, 16)))명사 추출 결과로 말뭉치를 생성 후, 문장부호 제거, 수치 제거, 소문자 변경, 불용어 제거 순으로 전처리를 진행했다. 불용어의 경우, 영어를 포함하여 “때문”, “이것”, “그것”, “들이”, “해서”, “무엇”, “저들”, “이번”, “우린”, “우리”를 선별했다.
“우리”와 “우린”의 경우에는 빈도수가 50회 이상으로 두 번째로 빈도수가 많은 “우크라이나”(22회) 보다 압도적으로 많아 단어 구름에서 상대적으로 빈도수가 적은 단어들이 지나치게 축소된다는 결점이 있었고, “우크라이나”와 “우리”, “우린”은 맥락 상 동일하므로 제거하여도 “우크라이나”라는 단어로 충분히 강조된다고 판단했다. 또한 “너희들”과 같이 모호한 단어에 대해서는, 영어 번역본에서 러시아를 “you”로 강조한 점[1]이 유의하다고 판단해 불용어 처리하지 않았다.
“우크라이나”와 같이 비교적 길이가 긴 단어를 추출해야 하므로, wordLengths를 4부터 16으로 설정했다. 아래는 위 과정의 결과 (zelcorpus3) 이다.
> zelcorpus3
<<TermDocumentMatrix (terms: 218, documents: 70)>>
Non-/sparse entries: 340/14920
Sparsity : 98%
Maximal term length: 6
Weighting : term frequency (tf)
단어 구름 생성
zelcor_df2 <- as.data.frame(as.matrix(zelcorpus3), stringsAsFactors = F)
dim(zelcor_df2)
wordResult2 <- sort(rowSums(zelcor_df2), decreasing=TRUE)
wordResult2[1:50]
zelname <- names(wordResult2)
word.df <- data.frame(word = zelname, freq=wordResult2)
word.df2 <- subset(word.df, subset = freq >= 2)
head(word.df2)
str(word.df2)
wordcloud2(data = word.df2,
size = 1, color = 'random-light', gridSize = 1,
backgroundColor="black"
, maxRotation = -pi/5, minRotation = -pi/2, shape = "circle")단어 구름을 생성하기 위해 데이터 프레임을 만들고, 빈도수를 내림차순으로 도출했다. 아래는 내림차순 50개 단어 중 일부 목록이다.
| 우크라이나 | 승리 | 너희들 | 사람 | 여기 | 당신 |
| 22 | 10 | 10 | 9 | 8 | 6 |
| 국가 | 영광 | 영웅 | 항복 | 대통령 | 자유 |
| 6 | 6 | 6 | 5 | 5 | 5 |
| 러시아 | 전쟁 | 독립 | 죽음 | 세계 | 위대 |
| 5 | 5 | 4 | 4 | 3 | 3 |
| 여러분 | 증명 | 질문 | 무기 | 지도자 | 처벌 |
| 3 | 3 | 3 | 3 | 3 | 3 |
| 불구 | 조상 | 약속 | 국민 | 이룩 | 정상 |
| 3 | 3 | 2 | 2 | 2 | 2 |
| 하나 | 최소한 | 대상 | 자식 | 수호자 | 수백만 |
| 2 | 2 | 2 | 2 | 2 | 2 |
전처리에서 의도했던 대로, “우크라이나”가 가장 큰 빈도수인 22회로 도출됐음을 확인할 수 있다. 또한 “사람들”이 유의어 처리되어 “사람”으로 9회 도출되었고, “당신” 역시 6회 도출되었다. 그 외에 불용어 처리한 것들이 제거되어 빈도에 따른 의미를 분석하기에 적절하다. 빈도수가 1회인 것은 크게 유의하지 않다 판단해 제거한 후 단어 구름을 생성한 결과는 아래와 같다.
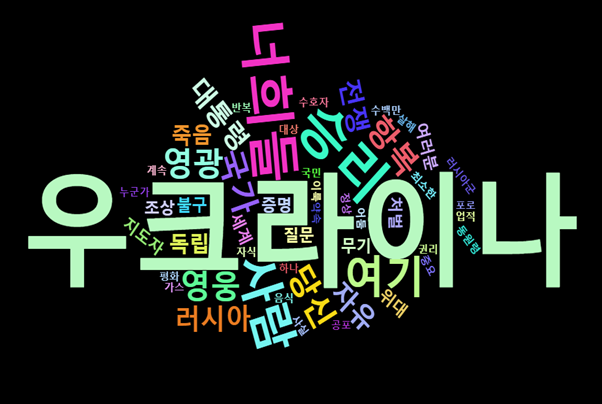
결과 분석
시각화 결과, 빈도분석과 동일하게 “우크라이나”가 최빈 단어로 도출되었음을 볼 수 있다. “승리”, “전쟁”, “항복”, “국가”와 같은 단어를 통해 전쟁이라는 특수한 상황에 놓여 있는 우크라이나를 확인할 수 있었다. 또한 영어 번역본으로는 “you”, 그리고 한국어 번역본으로는 “너희들”이라는 다소 강한 표현을 함으로써, 강한 태도를 표출하고 굳건한 모습을 드러냈다.
그리고 “여러분”과 같이 청자를 지속적으로 지칭함으로써 주의를 집중시키고 관심을 끌고 있다. 우크라이나의 지도자로서 강한 태도를 보임으로써 국민들에게는 안심을 주고, 국제사회의 지원과 도움을 효과적으로 요청할 수 있었을 것이며, 적인 러시아에게는 굴복하지 않는 모습으로 보였을 것이라고 해석된다.
소스 코드
library(KoNLP)
library(tm)
library(multilinguer)
library(wordcloud)
library(wordcloud2)
library(stringr)
library(tidytext)
setwd('c:/Rwork')
raw_zel <- readLines("zelensky.txt", encoding = "UTF-8")
head(raw_zel)
#우크라이나 단어 추가
user_dic <- data.frame(term = c("우크라이나", "러시아"), tag = "ncn")
buildDictionary(ext_dic = "sejong", user_dic = user_dic)
####1번(단어구름)####
#유의어 수정
raw_zel <- str_replace_all(raw_zel, "사람들", "사람")
raw_zel <- str_replace_all(raw_zel, "영웅들", "영웅")
raw_zel <- str_replace_all(raw_zel, "당신들이", "당신")
#명사 추출
exNouns <- function(x){paste(extractNoun(as.character(x)), collapse = " ")}
zel_nouns <- sapply(raw_zel, exNouns)
zel_nouns[1]
#단어 대상 전처리하기
zelcorpus <- Corpus(VectorSource(zel_nouns))
#문장부호 제거
zelcorpus2 <- tm_map(zelcorpus, removePunctuation)
#수치 제거
zelcorpus2 <- tm_map(zelcorpus, removeNumbers)
#소문자 변경
zelcorpus2 <- tm_map(zelcorpus, tolower)
#불용어 제거
myStopwords = c(stopwords('english'),
"때문", "이것", "그것", "들이", "해서",
"무엇", "저들", "이번", "우린", "우리")
zelcorpus2 <- tm_map(zelcorpus, removeWords, myStopwords)
#전처리 결과 확인
inspect(zelcorpus2)
#단어 선별하기
zelcorpus3 <- TermDocumentMatrix(zelcorpus2,
control = list(wordLengths = c(4, 16)))
zelcorpus3
#데이터프레임으로 변경
zelcor_df2 <- as.data.frame(as.matrix(zelcorpus3), stringsAsFactors = F)
dim(zelcor_df2)
#빈도수 구하기
wordResult2 <- sort(rowSums(zelcor_df2), decreasing=TRUE)
wordResult2[1:50]
#단어 구름 적용
zelname <- names(wordResult2)
word.df <- data.frame(word = zelname, freq=wordResult2)
#빈도수 2 이상
word.df2 <- subset(word.df, subset = freq >= 2)
head(word.df2)
str(word.df2)
#단어 색상과 글꼴 지정
wordcloud2(data = word.df2,
size = 1, color = 'random-light', gridSize = 1,
backgroundColor="black"
, maxRotation = -pi/5, minRotation = -pi/2, shape = "circle")
[1] Without gas or without you? - The answer is without you. 영어 번역본 일부 발췌
'R > 실습(project)' 카테고리의 다른 글
| [R/실습] ggplot2를 이용한 iris 데이터 시각화 (0) | 2023.01.03 |
|---|---|
| [R/실습] Zelensky 대통령 연설문 모음 텍스트 분석 - 연관 분석 (0) | 2022.12.20 |
| [R/실습] 선형회귀분석을 이용한 BostonHousing 예측분석 (0) | 2022.12.20 |
| [R/실습] 의사결정나무를 이용한 BostonHousing 예측분석 (0) | 2022.12.20 |
| [R/실습] 랜덤포레스트를 이용한 위스콘신 유방암 데이터 분류분석 (0) | 2022.12.20 |

댓글